Human Rights First: Asylum Seekers is a law firm that specializes in immigrants seeking asylum in the US. Our job was to make an app that could take in Asylum legal PDFs, extract important information, and add them to a database for users to search. I used pdfminer to scrape the PDFs for text and then used Spacy entity recognition and matching to to find the judges name in the PDF:
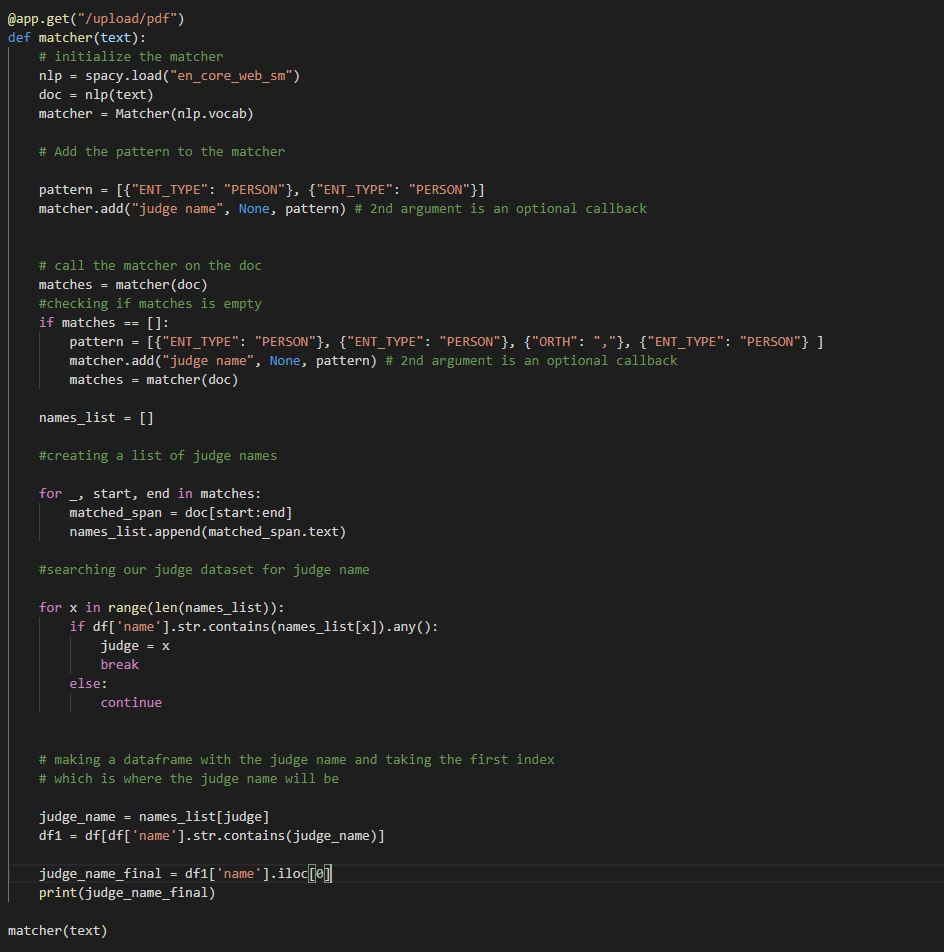
First, I had to deal with names being written in a certain order i.e. George, J. Unfortunately, the judges name isn’t always written in full on the PDFs, but I got around this by using a list of judges and their appointees and checking if that name was in the list of judges. I found that the judge name was always the first one written so I looped through the judge list to see if that name is in the list. After that, I created a dataframe with the judges full name from the judge list, and returned the first index in that dataframe to get the the judge’s full name.
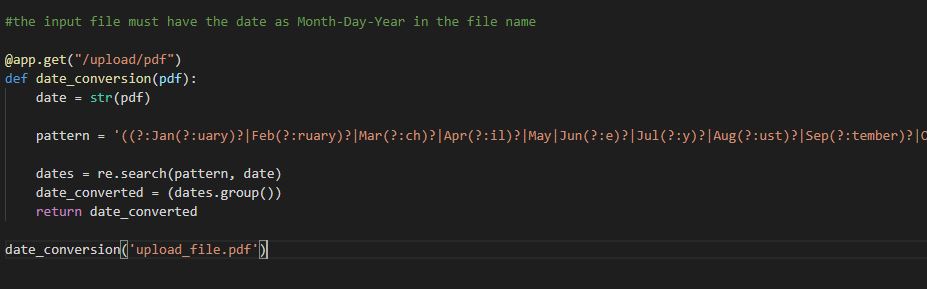
I also made a Regex scraper that gets the date directly from the PDF title since all the legal PDFs followed this same format of the month written out in long form, then the day, then the year.
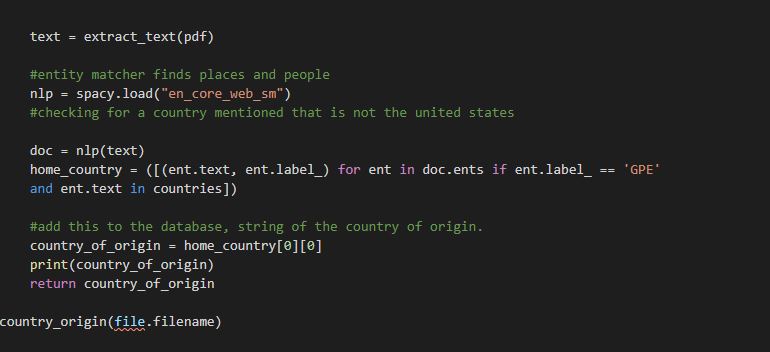
Finally, I found the country of origin that the Asylum seeker was from. I used Spacy entity matching for text and lables, and I wanted to see if it was in a list of all countries except for the United States. I parsed the text then returned the country of origin.
Unfortunately the lawyer didn’t get back to us in time with keywords we needed to parse the legal jargon by the time were finished with our allotted time for the project, but I managed to get several important features using the methods I outlined above.
Here is all of the scripts running and working:

Finally, I worked with the other data scientists to get it deployed on fastAPI and working with Amazon Web Services. It just took a little pair programming to get the scripts imported and working.